




Just How Big Of An Axe Should You Take To Your Content?
It wasn’t that long ago when we used to collect as much data as possible from members in the hope that some of it would be useful.
We encouraged members to share real names, gender, phone numbers, email addresses, birthdays, photos, and more.
Then GDPR happened, and data suddenly shifted from a potential asset to a potential liability (or, as the saying goes, data went from the new oil to the new uranium).
Now almost all organisations have strict rules in place to ensure it’s handled with care.
Which means even small organisations like mine, FeverBee, are ISO 27001 certified to work with enterprise clients (and even then, we often still need to complete questionnaires with 100+ questions).
Content is now following a similar path.
What Is Content Hoarding And Why Do Organisations Do It?
Let’s expand the definition of content here to include everything that might appear in a community:
- Questions & Answers
- Blog posts
- Ideas
- Knowledge articles
- Videos etc…
The largest communities have millions of items of content collected over a decade or more.
And many have done little to archive, merge, or remove any of it.
This is known as content hoarding.
It means conversations from 2008 about products that are no longer supported and that no one has visited in over a decade are still sitting side by side with the discussions created yesterday.
And like any other kind of hoarding, it’s kept around for two reasons:
- The hope that one day it will be useful to someone.
- A representation of success/ideals (look at all the content we’ve generated!)
This is perpetuated by a simple third belief that it doesn’t do any harm.
Unlike real-world hoarding, where the downsides (mess, reduced space, etc) are real and visible. Digital hoarding feels harmless.
Unfortunately, the hidden costs are higher than you imagine.
The Incredibly High Hidden Costs Of Digital Hoarding
There are three major problems with content hoarding.
{kind=link}

1) It negatively impacts search traffic.
Search engines allocate a certain ‘crawl budget’ to each site.
This is the number of URLs the Google bot will visit in your community and consider for inclusion in its search index (from which it retrieves search results).
Any content that isn’t crawled won’t make it into the index and can’t be retrieved by search results.
The crawl budget isn’t allocated equally across all sites. It’s impacted by ‘crawl demand’ – essentially the popularity, freshness, and usefulness of the site itself.
The more high-quality content it sees (recent, popular, and uniquely useful), the more it will want to crawl the rest of the site.
However, if the Google bot encounters a lot of outdated, unanswered, or simply unpopular content, the crawl budget will shrink drastically (i.e., it won’t want to crawl the rest of the site). This is a big problem for hosted communities with discussions that are 5 to 20+ years old.
Many folks still think having lots of content = a greater chance of attracting search traffic due to the many possible long-tail terms. But today, the opposite is true. Taking the archiving axe to huge swathes of content is how you grow engagement and participation.
Aside – Last year, we helped one client archive 80% of their content and achieved a 32% uplift in search traffic (despite prevailing counter-forces).
2) It Distorts The Results Of LLMs And RAG Search
As I’ve frequently discussed of late, content hoarding is a direct path to confusing LLMs and internal AI tools (watch video).
Most enterprise organisations are currently racing to integrate community data into AI-powered support layers. These systems rely on retrieval-augmented generation (RAG) to fetch community content and synthesize answers for customers.
The fundamental problem is that RAG systems are often ‘timestamp blind.’ They don’t recognize when a 2016 solution has been superseded. They treat a legacy answer with dozens of upvotes with the same, or greater, authority as a modern, correct response from last month.
This means an accepted answer from a decade ago might be entirely wrong today, yet the AI serves this outdated information to your customers with absolute confidence. Often, nobody even realizes the damage is being done until the complaints start flooding in.
It gets worse. When multiple threads cover the same topic across different years, RAG systems often pull fragments from several sources. The result is a Frankenstein answer that blends advice from 2015, 2019, and 2024 into a single, internally contradictory response. The customer is left with no way to discern what is current and what is obsolete.
This is a problem that compounds over time.
The more ‘sludge’ you have, the higher the probability of retrieval error. And unlike search traffic, which can be measured, these bad RAG answers are largely invisible. You don’t get analytics on the erosion of trust occurring in your support channels.
We recently helped a client categorize over 100k threads using AI tagging. We discovered that the most-viewed content was almost exclusively beginner-level queries already covered in official documentation. The unique value of the community, the edge cases and experiential knowledge, was buried under a mountain of duplicated, unstructured noise that no RAG system could reliably parse.
Organisations that proactively clean and structure their community content now will gain a significant competitive advantage. Those that don’t risk seeing their communities excluded from knowledge indexes entirely because AI teams will deem the data too unreliable to use.
3) It Creates A Significantly Worse Experience For Members.
When members search for help, they don’t want a dozen possibilities; they want the single, most up-to-date answer. Or, at the very least, they want to know the answer doesn’t exist so they can ask the question themselves.
Hoarding content makes both of these outcomes unnecessarily difficult.
In our member interviews, landing on outdated discussions is consistently a top grievance. Members arrive via search, follow an ‘accepted solution,’ and discover it no longer works because the product or API has changed. Yet, there is no indication on the page that the information is of a different vintage.
This isn’t just a minor annoyance; it drastically reduces CSAT. It destroys the metrics that matter most: time-to-resolution and perceived quality. If a member wastes 15 minutes on a dead-end solution, they’re unlikely to use your community again.
There is also a decision paralysis effect. Faced with dozens of near-identical threads spread across years, most users won’t dig through the pile. They’ll either guess, and likely fail, or abandon the community entirely to open a costly support ticket instead.
With one client, we found that outdated information was a top-five problem in their satisfaction surveys. After we archived roughly 80% of the content (the same project that saw a 32% search traffic uplift), that issue vanished from the top ten. Members didn’t miss the old content; they were relieved it was gone.
Finally, consider the newcomer problem. Knowing there are 1.3 million articles sounds daunting, not inviting. A community with 10,000 well-maintained discussions says “we have answers.” A community with 1.3 million threads feels like it’ll be far more effort to find what you want.
The Community Knowledge Audit
Over the past year, we’ve helped several organisations tackle this problem. The approach has crystallised into something we’re calling the Community Knowledge Audit, a six-layer process for transforming messy community data into a trusted, AI-ready knowledge asset.
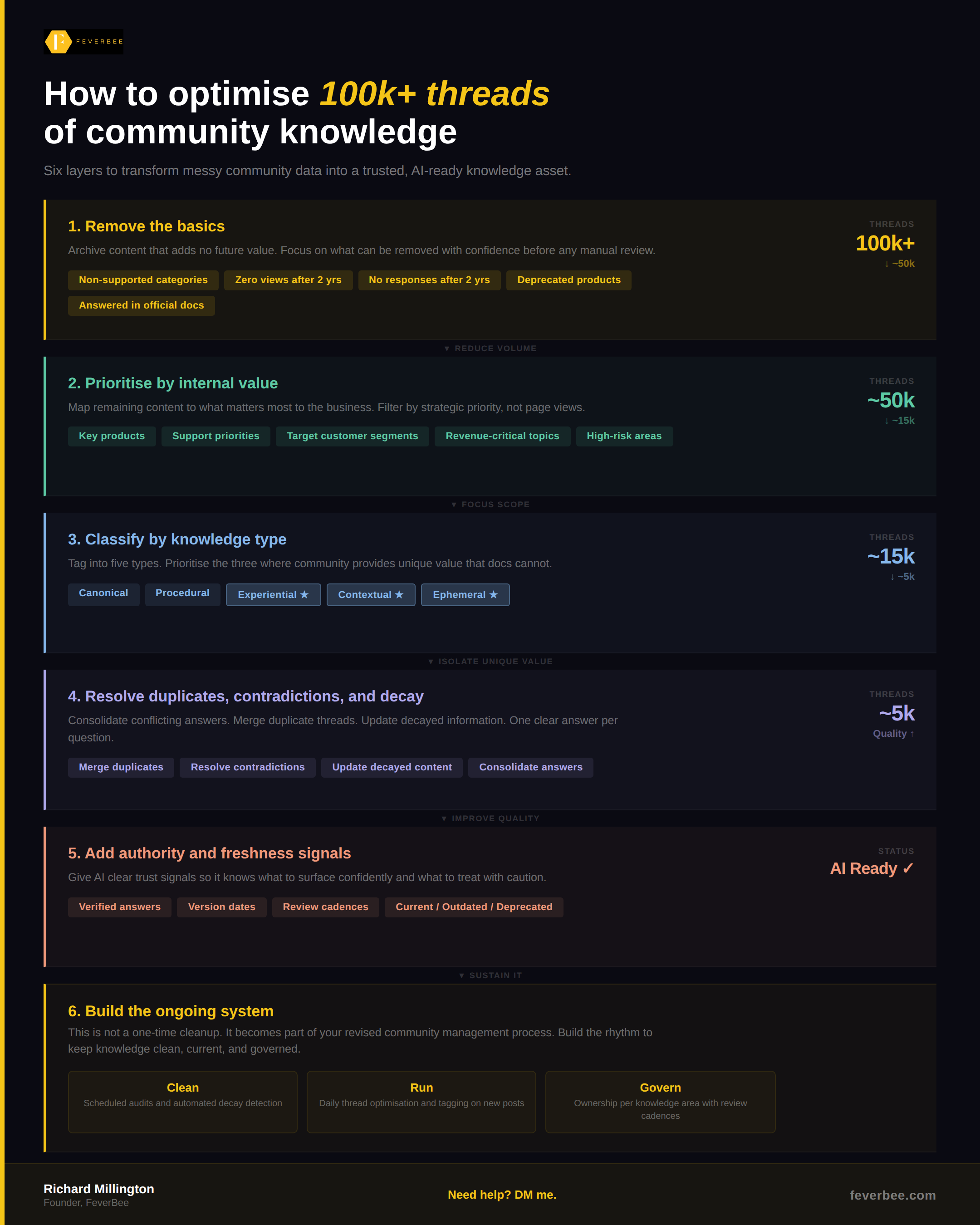{kind=link}
The core idea is simple: you don’t try to fix everything. You progressively filter, prioritise, and improve, so your effort goes where it actually matters.

Here’s how it works.
Layer 1: Archive The Fundamentals. Start with what can be removed with confidence before any manual review. This might include content in non-supported categories, threads with zero views in two years, discussions with no responses after two years, content tied to deprecated products, and anything already answered comprehensively in official documentation. For most large communities, this alone reduces the number of threads from 100k+ to around 50k.
Layer 2: Prioritise by internal value. Map what remains to what actually matters to the business. Filter by strategic priority, not page views. That means focusing on key products, support priorities, target customer segments, revenue-critical topics, and high-risk areas. This typically narrows the field to around 15k threads worth investing effort in.
Layer 3: Classify by knowledge type. Tag every remaining thread into one of five types: canonical, procedural, experiential, contextual, and ephemeral. The community’s unique value lives in the experiential and contextual discussions, the edge cases, and real-world advice that official docs can’t provide. Prioritise those. This focuses your effort on roughly 5k threads that represent the community’s genuinely irreplaceable knowledge.
Layer 4: Resolve duplicates, contradictions, and decay. Now you’re working with a manageable set. Merge duplicate threads. Resolve contradictory answers. Update decayed information. The goal is one clear, current answer per question. This is where quality improves dramatically.
Layer 5: Add authority and freshness signals. Give AI systems (and members) clear trust signals. Mark verified answers. Add version dates. Establish review cadences. Label content as current, outdated, or deprecated. This is what makes your community content reliably retrievable by RAG systems and internal AI tools.
Layer 6: Build the ongoing system. This isn’t a one-time cleanup. It becomes part of your revised community management process. That means scheduled audits and automated decay detection (Clean), daily thread optimisation and tagging on new posts (Run), and ownership per knowledge area with review cadences (Govern).
Most organisations can start seeing results within weeks, not months. The effort compounds. Even five discussions a day, properly targeted, add up to hundreds over a quarter – and thousands over a year or two.
The hardest part isn’t knowing what to do. It’s getting started when you’re staring at six figures worth of threads and no clear entry point.
If your team is stuck at that stage, that’s very much the kind of problem we help organisations solve. Drop me a message, and we can figure out where you are.